Scalable-Health-Data-Solutions-GCP
🏥 Scalable Health Data Solutions & Big Data ML Pipelines 🚀
🌟 Project Overview
This project demonstrates a dual-lens approach to Big Data in Healthcare. It bridges high-level Cloud Strategy (GCP) with hands-on Distributed Machine Learning (PySpark) to solve critical industry challenges like early disease detection and treatment cost optimization.
🛠️ Technical Execution: PySpark ML Pipeline 📊
I developed a high-performance machine learning workflow using Apache Spark to handle large-scale data processing. This pipeline automates the journey from raw data ingestion to multi-model evaluation.
🧩 Core Engineering Workflow
To ensure data integrity and scalability, I implemented a modular PySpark pipeline:
Feature Engineering & Transformation Workflow
imputer = Imputer(inputCols=["Age", "Fare"], outputCols=["Age_imputed", "Fare_imputed"])
indexers = [StringIndexer(inputCol=col, outputCol=col + "_Index") for col in ["Sex", "Embarked", "Pclass"]]
encoders = [OneHotEncoder(inputCol=col + "_Index", outputCol=col + "_Vec") for col in ["Sex", "Embarked", "Pclass"]]
assembler = VectorAssembler(inputCols=["Age_imputed", "SibSp", "Parch", "Sex_Vec", "Embarked_Vec", "Pclass_Vec"], outputCol="features")
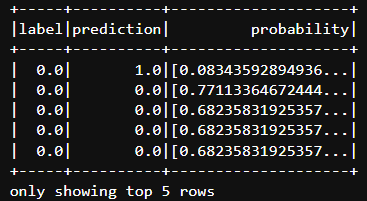
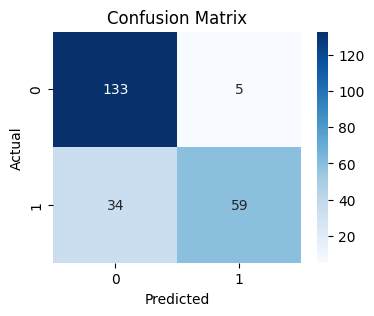
🖼️ Model Performance & Data Insights
| 📈 Model Predictions | 📉 Confusion Matrix | 📋 Data Engineering |
 |
 |
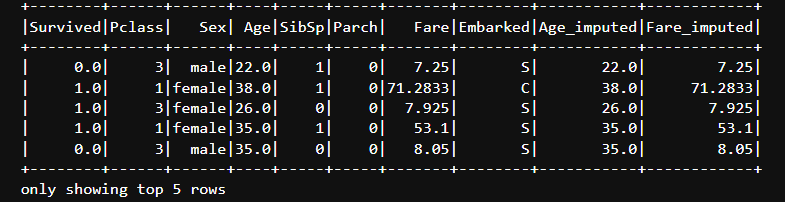 |
| Real-time prediction scores | Accuracy breakdown (83.12%) | Cleaned ETL output |
🏆 Key Metrics SummarySurvival Prediction (Random Forest):
-
Achieved an Accuracy of 83.12% and an F1-Score of 0.8236.
-
Fare Prediction (Linear Regression): Evaluated with a Root Mean Squared Error (RMSE) of 40.75 and an R-Squared ($R^2$) of 0.40.
🧬 Phase 1: Strategic Healthcare Case Study
💡 Business Problem & Opportunity
-
The Challenge: Diagnosis often happens after symptoms appear, increasing patient mortality and long-term costs.
-
The Solution: Utilizing real-time data from wearables to proactively detect early warning signals.
-
Business Value: Lowering hospital readmissions and overall cost burdens on providers.
🌐 The 3 Vs of Health Data
-
Volume: Managing thousands of daily data points across millions of users.
-
Velocity: Continuous data streaming via Bluetooth for near real-time anomaly detection.
-
Variety: Integrating physiological, behavioral, and patient-reported data.
☁️ Essential Cloud Services (GCP Stack)
I proposed a Google Cloud Platform architecture to support scalable health analytics:
-
BigQuery: For scalable data warehousing and integrating streaming data with Electronic Health Records (EHRs).
-
Cloud Dataflow: To process real-time streams and trigger alerts for detected anomalies.
-
Vertex AI: For building and deploying health risk prediction models.
-
Cloud Healthcare API: Ensuring HIPAA compliance and protecting sensitive patient data.
🧰 Tools & Technologies
-
Big Data Framework: Apache Spark (PySpark MLlib)
-
Language: Python
-
Analytical Libraries: Pandas, Seaborn, Matplotlib, Scikit-learn
-
Cloud Strategy: Google Cloud Platform (GCP)
📜 License
This project is licensed under the MIT License.
👤 Author
Tejashwini Saravanan LinkedIn